NVIDIA 推出为中国市场量身定制的 RTX 4090D 显卡(以下简称“4090D”)。
NVIDIA 对该显卡的参数进行了特别调整。RTX 4090D 的设计严格遵循了 TPP(总处理性能)的限制,配备了14592 个 CUDA 核心,加速频率达到 2.52 GHz,并搭载了 24GB 384bit GDDR6X 显存。
参数可以做简单对比,实际性能却不能简单换算,可能面临模型、推理框架、算力墙、显存墙等多种因素影响,端到端的性能评测是一个非常复杂严谨的事情。
借着这次派欧算力云(www.paigpu.com) 4090D 资源上线,我们也为大家提供一份完整的性能评测报告!
NVIDIA 4090D 规格参数解析

GeForce RTX 4090D采用了 NVIDIA Lovelace 架构,5nm 制程工艺, 配备了 14592 个 CUDA 核心、24GB GDDR6X 内存、384 位宽内存总线和 425W 额定功耗。
与RTX 4090相比,RTX 4090D在核心数量和功耗上有所降低。其中,RTX 4090D 的 CUDA 核心减少了 12.8%,从 16384 个降至 14592 个、128 个流处理器减至 114 个,而功耗也略微下降了5.9%,从450W降至425W。
在其他核心规格上,RTX 4090D 与 RTX 4090 相同。比如,384位的宽内存总线,24GB GDDR6X 显存,以及最高可达2.52GHz的加速频率。唯一的区别是基准频率略有提升,从 2.23 GHz 调整到 2.28GHz,但有点遗憾的是,4090D 并不支持超频。
从性能参数推算,4090D 相当于是发挥了 90% 性能的 4090。
性能评测方法和数据
为了深入了解在实际应用场景中 4090D 的表现,我们选择了当下风靡的 Stable Diffusion (以下简称“SD”)和大语言模型 Llama 对此进行了性能测试。
Stable Diffusion 测试
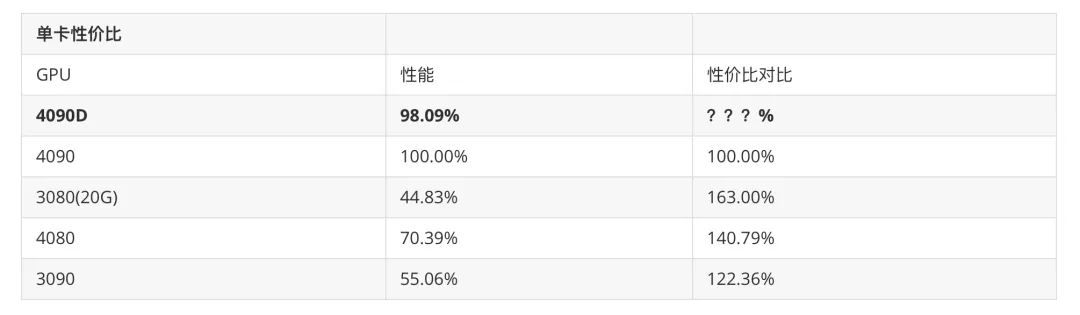
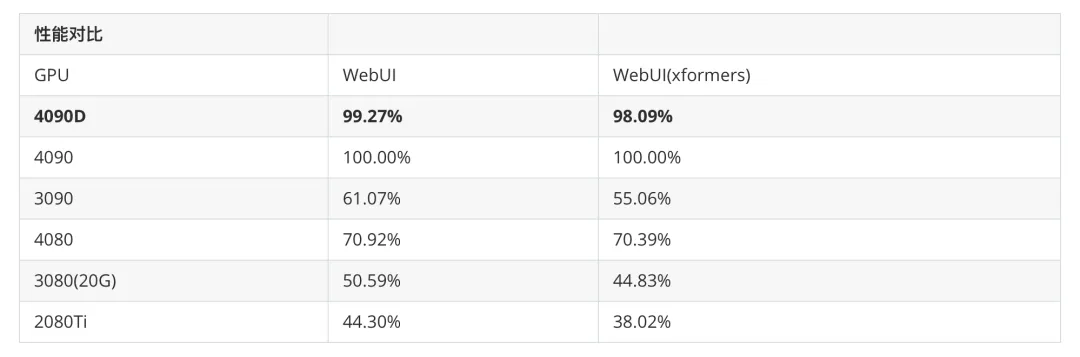
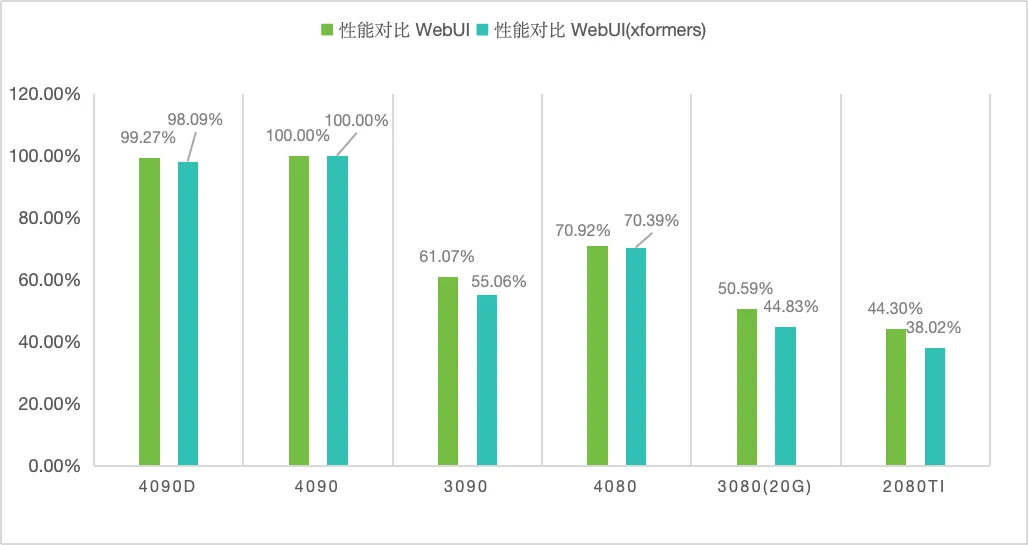
在 SD 测试中,我们以 4090 为基准,同时结合目前市面上热门的其他显卡,制定了两个指标用于衡量 4090D,分别为“单卡性价比”和“性能对比”测试。
SD性能对比方法
在SD_V1.5基础模型,默认采样器,512*512分辨率下,生成每张图的耗时。
SD性价比对比方法
结合算力的时间成本,对比RTX4090与RTX4090D,生成每张图片的价格。
单卡性价比:
性能对比:
大语言模型推理(Llama2)
在大语言模型的测试中,我们以 4090 的性能作为基准值,分别选用了不同规格的 Llama 模型进行了多轮测试,最终梳理出了以下结果。
LLM性能对比方法
指定输入/输出参数长度下,对比每秒生成的Token数量。
LLM性价比对比方法
结合算力的时间成本,对比RTX4090与RTX4090D,生成每个Token的价格。如每小时算力成本1元,每小时生成Token数为100个,则性价比就是1分钱/Token。
性能对比:

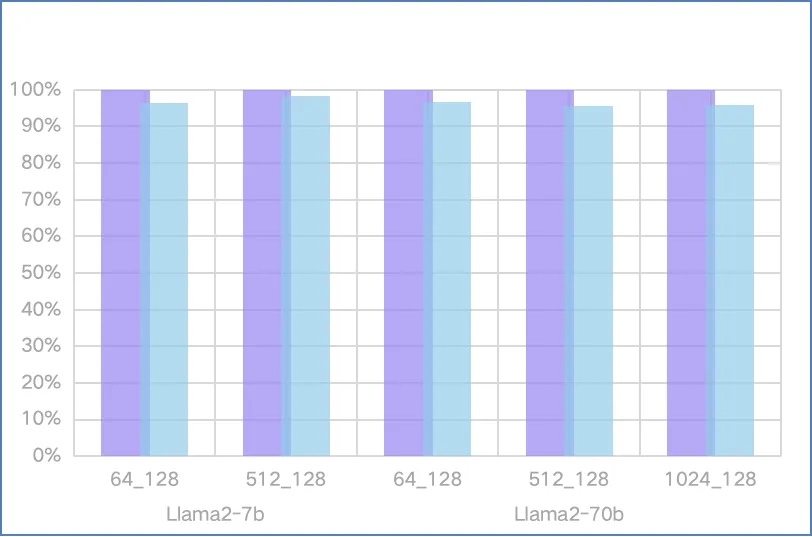
LLM推理性价比:

评测结论
通过上面的测试数据,我们得出以下结论。
1、在 SD 测试中,4090D 的性能约为 4090 的 98%-99%。
2、在 Llama2-7b 的测试中,4090D 的性能约为 4090 的 96.5%。
3、在 Llama2-70b 的测试中,4090D 的性能约为 4090 的 97%。
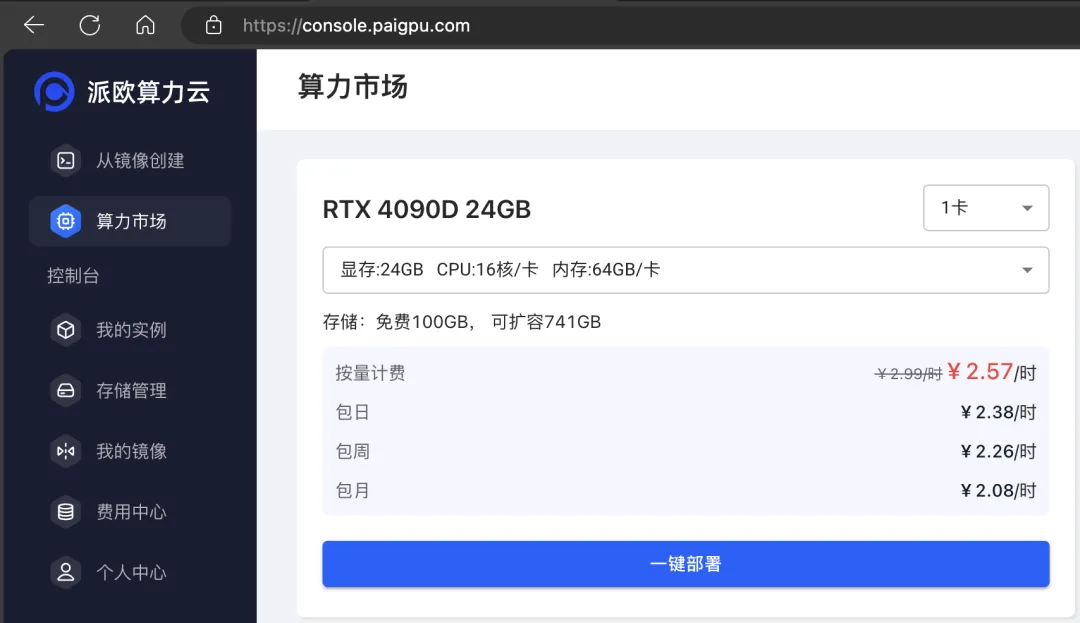
试用方法
如果抛开性能,单从机房建设的性价比上来说,在不考虑合规与溢价的条件下,4090D 的整体建设性价比约为 8 卡 4090 服务器的 120%。如今,机器学习、生成式人工智能浪潮席卷全球,不少企业都陷入一卡难求的窘境,此时,选择高性价比的 GPU 云服务受到了越来越多企业的青睐。
派欧算力云全网首发上线,正式上架 NVIDIA GeForce RTX 4090D ,您可以在算力市场一键部署。按需计费、弹性伸缩的特性,不仅为您免去了高昂的建设成本和运维成本,更有涵盖多种运行环境和应用场景的海量镜像供您选择,您可以根据自己的需求快速选择并部署,大幅节省环境配置的时间,提高开发效率。